In my role as a developer for Telesmart, I've found myself working with Microsoft's Graph API - and have implemented a Graph API MicroService in GraphQL. I've also recently been working on a side project to calculate Bacon Numbers for both actors/actresses and movies, and for this I've been using a Graph DB - Neo4J. So, just why do these technologies have the word Graph in them, and how are they related? Let's find out!
Our Graph Technologies
Here is a very simple breakdown of what each of these technologies does, and what it is useful for:
Graph API
We'll start with the simplest to explain, which is the Microsoft Graph API. This API is an effort by Microsoft to give customers a single place they can query their data across all of Microsoft's services - such as Active Directory (user accounts, permissions, etc), Office 365, Teams and Sharepoint. It's a work in progress, as there's still a lot that needs to be added, but it's a promising start.
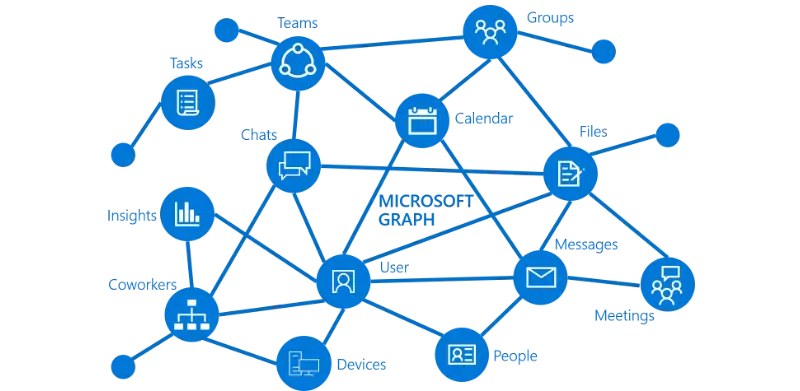
The API is a REST API, with endpoints such as /me (to get your own user info), /users (to see details of all users in your domain) and /me/drive/root/children (to list your oneDrive files). There are libraries for Node (Javascript) and other languages that make querying the API easier, and there is support for pagination, filtering, etc.
GraphQL
GraphQL is a modern alternative to a more traditional Rest API, and was invented by engineers at Facebook several years ago. Rather than REST's multiple endpoints (URLs), where endpoints Are the way that you query data, GraphQL just has a single endpoint (usually /graphql) that you send your HTTP requests to. The clever thing about GraphQL is the use of an empty object as the data you send to the server - you choose which data fields you want returned in the API response by only adding keys for those fields in your empty object. The server then responds with an object (or set of objects) that match the empty object you sent to it, but with the data populated.
Example Query
If, for example, we sent this empty data object as a query to a GraphQL server with movie data:
{
movie(id: "tt0019254") {
title
year
genres {
id
title
}
writers
}
}we would receive this response:
{
title: "The Passion of Joan of Arc",
year: 1928,
genres: [
{
id: 3,
title: "Biography"
},
{
id: 9,
title: "Drama"
},
{
id: 17,
title: "History"
}
],
writers: ["Joseph Delteil", "Carl Theodor Dreyer"]
}In the backend, this is achieved through writing a Schema (which describes the data and how it's related) and Resolvers (which get the data, and make any necessary joins). It can feel a little verbose at times, but the effort required in the backend is worth it when you come to consume your data in the frontend - especially if you use a Javascript library such as the Apollo GraphQL client, which I do for my Nuxt projects.
This concept is really quite clever, making fine-grained control of what data you want in your frontend a simple task, and making it easy to ensure you're not using bandwidth unnecessarily. I've fallen in love with GraphQL in the last couple of years, and use it wherever possible in my projects.
For more information on how GraphQL came about, there's a great documentary:
Graph DB
A Graph DB is a form of NoSQL database where data is stored as "nodes", and "edges" can be used to represent relationships between nodes. These relationships are themselves objects that can have properties. This type of database can perform some types of complex calculations more quickly than traditional SQL or even newer NoSQL databases can.
For my use case, I use a shortest path algorithm to calculate the Bacon Number for movies. Once my dataset (an export of IMDB data) has been loaded into the database, these queries can run very quickly.
So, how are they related?
Quite simply, they're not! Microsoft uses the name Graph API to denote that their technology connects all of their services behind a single API. But that API is queried using REST HTTP requests (and not shiny GraphQL queries), and (as far as I can tell) Microsoft aren't using a Graph DB to model the connections between their data sources.
Similarly, GraphQL is just a layer between your frontend clients and your backend data, providing a simple way to query that data. GraphQL is not a Graph Database, and doesn't deal with the storage of your data.
Finally, a Graph DB allows you to store data objects and define the relationships between those objects. You can then run efficient queries on that data that use both the data and the relationships to build your response. But how you query that data depends on the database, and at the moment I don't think that any Graph Databases use a native GraphQL querying layer - rather, a query language called Cypher is commonly used.
There's nothing to stop you using a Graph DB as the backend data store for a GraphQL API layer, or (as I have done for work) writing a GraphQL layer on top of Microsoft's Graph API. However, there's nothing special or magical about a "Graph" that connects these three disparate tools.
These are all clever, useful technologies, and I guess that, to an extent, they all have some justification for using the word "Graph" in their name. But they're not related, and they don't rely on each other.